
“L’intelligenza non può essere presente senza capire.
Nessun computer ha alcuna consapevolezza di quello che fa”
Roger Penrose
Roger Penrose
L’avvento dell’intelligenza artificiale e delle nuove tecnologie digitali è stato descritto come la “quarta rivoluzione industriale”. In particolare secondo Klaus Schwab – fondatore e già presidente del World Economic Forum, che si svolge ogni anno a Davos in Svizzera – “la nuova rivoluzione tecnologica è la più affascinante e suggestiva, poiché comporta una vera e propria trasformazione per l’umanità. Siamo alle soglie di una rivoluzione che sta cambiando drasticamente il modo in cui viviamo, lavoriamo e ci relazioniamo con gli altri. Se ne valutiamo la portata e la complessità, quella che io considero la quarta rivoluzione industriale è qualcosa con cui l’uomo non ha mai dovuto confrontarsi prima d’ora”.
Come tutte le rivoluzioni, quella che stiamo attualmente vivendo riguarda e riguarderà, in particolar modo, le giovani generazioni.
Quali sono quindi le sfide future, sia sul piano tecnologico che su quello etico-sociale? che dobbiamo prepararci ad affrontare? Quali le opportunità? E quali i rischi?
Per cercare delle risposte alle tante domande che affollano la mia mente, un giorno ho trovato sul web un’interessante intervento al TEDxBari, di Giulio Deangeli, che, a soli 29 anni, è considerato uno dei più grandi neuroscienziati al mondo.
Il titolo è: “Come pensa un’intelligenza artificiale?”
Nell’occasione il giovane scienziato prova a trasmettere al pubblico tre concetti, rispondendo alle seguenti domande:
Cosa fa l’IA Tradizionale?
Fino a qualche tempo fa con il termine “Intelligenza Artificiale” si intendeva una famiglia di tecniche, meglio note come tecniche di deep learning, che si avvalgono di reti neurali. Cosa fanno le reti neurali? Sostanzialmente due cose classificazione e regressione.
Partiamo dalla prima. Per far capire meglio il concetto di classificazione, farò un esempio: prendiamo un dataset di dati relativi a vari animali e insegniamo alla rete a classificarli, ovvero a distinguere un cane, da un gatto, un cavallo etc. etc., come se mettessimo delle etichette su ciascun animale. Alla fine del training, ovvero dell’addestramento, avremo un programma informatico in grado di generalizzare. Ciò significa che se diamo alla macchina i dati di un certo animale quali peso, lunghezza e larghezza, questa sarà in grado di classificarlo, ovvero di dirci: “Romeo è un cane”, “Birba è un gatto” e così via.
Ecco una tabella che chiarisce il tutto.
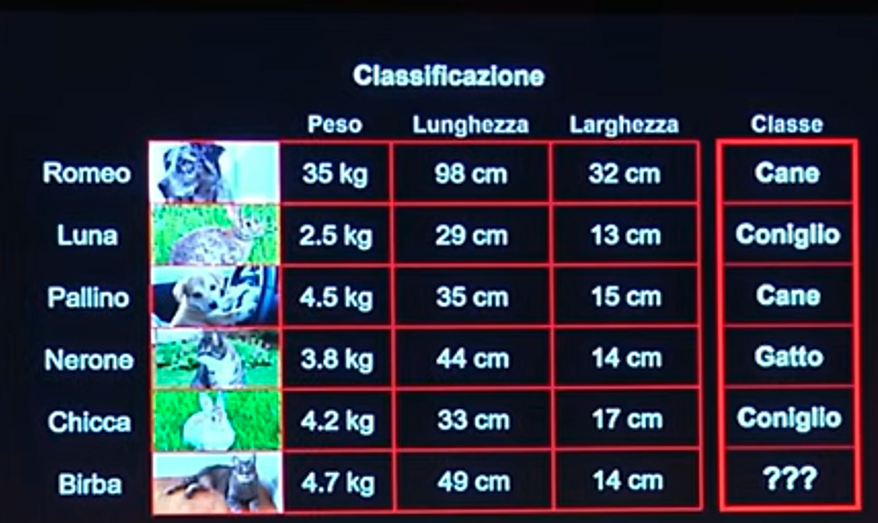
La regressione è la stessa identica cosa, solo che al posto di etichette, ovvero di classi, nella fase di addestramento si insegna alla macchina di stimare delle quantità numeriche.
In tal caso. dando in input gli stessi dati dell’esempio precedente, ovvero peso, lunghezza e larghezza, la macchina sarà in grado di indicare l’altezza dell’animale invece della classe.
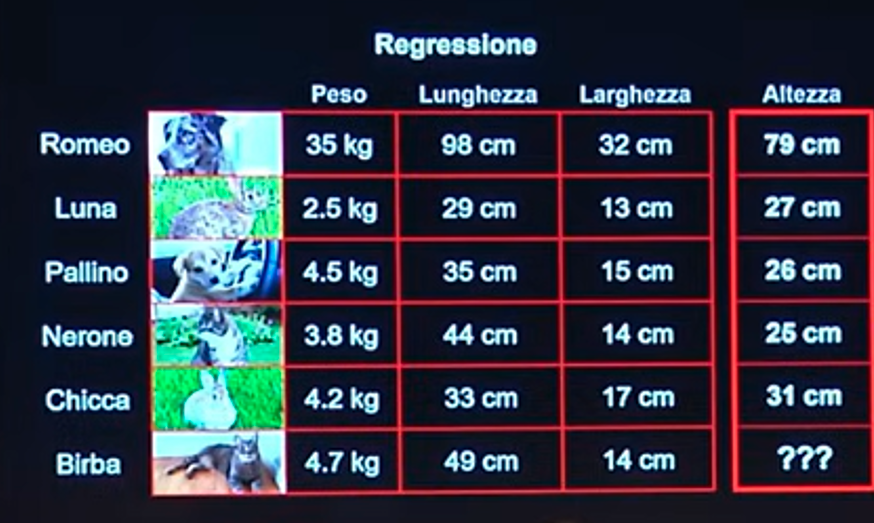
Prima di continuare è però necessario precisare che esiste sotto branca del machine learning, ovvero il deep learning, che altri non è che un approccio di machine learning nel quale, però vengono aggiunti dei filtri, che hanno il compito di rendere in forma sempre più utile i dati.
Come lo fa?
Le applicazioni di deep learning funzionano con Reti Neurali Artificiali (RNA), che simulano le reti neurali del nostro cervello. Storicamente vennero introdotte nel 1943 da un neurobiologo e da un matematico, McCullogh e Pitts, nel corso dei loro lavori di ricerca, i quali si proposero di simulare in un programma informatico il funzionamento di un neurone.
Cosa sono i neuroni e come funzionano?
Il neurone è una cellula che prende in input dei segnali elettrici da altri neuroni, tramite le sinapsi, li moltiplica per dei coefficienti, ovvero dei pesi, e infine li fa convergere in un solo numero.
Così come indicato in figura, il neurone moltiplica i segnali in ingresso per dei “pesi”, tramite i dendriti, rappresentati come dei “rametti” di diverse dimensioni, e li fa convergere in un punto dove vengono sommati. Se questa somma supera una certa soglia viene sparato una specie di proiettile, che altri non è che un altro segnale elettrico chiamato “potenziale d’azione”, che viene, quindi, propagato a valle, agli altri neuroni, tramite altre sinapsi.
Matematicamente cosa fa questo neurone? Prende dei segnali in ingresso, li moltiplica per dei coefficienti e li somma. Dopo di che applica una soglia, ovvero l’operazione tale per cui se il segnale è maggiore di un certo valore viene mandato avanti, altrimenti no.
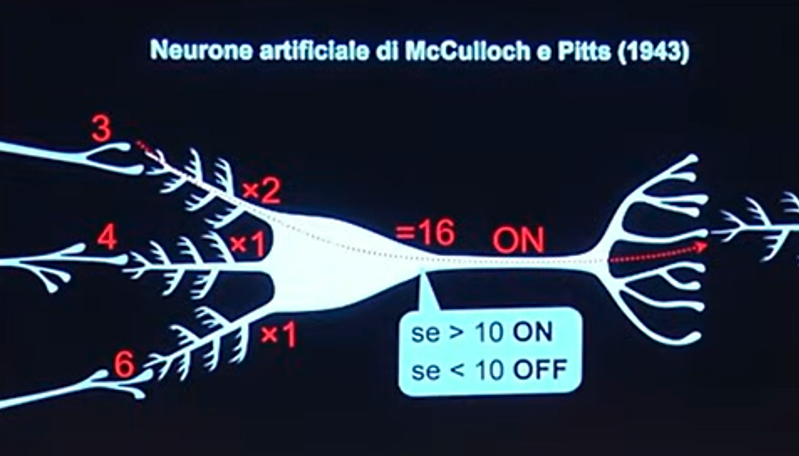
Il fatto che ci sia un’operazione di soglia è determinante, perché tutte le altre operazioni, somma, sottrazioni etc. sono operazioni lineari, la soglia è un’operazione non lineare, perché non è rappresentabile con una retta, bensì con uno scalino.
Osserviamo che tutta la complessità del nostro cervello e della vita, in generale, deriva proprio dal fatto che il neurone è una macchina non lineare.
Se facciamo un programma informatico che prende degli input, li moltiplica per dei coefficienti, li somma e li passa attraverso una soglia, abbiamo creato un neurone artificiale.
Se creiamo tanti neuroni artificiali e li mettiamo in fila su di una serie di layer, abbiamo realizzato una rete neurale, come in figura (1° layer: 7 neuroni, 2° layer: 4 neuroni, 3° layer: 7 neuroni):
Se addestriamo la nostra rete neurale con un certo trucco matematico, possiamo insegnare a questa rete neurale a fare classificazione e regressione, come abbiamo visto prima.
Come funziona una IA generativa come ChatGPT?
Passiamo ora alla seconda domanda. Come fa un computer ad inventare cose da nuove? Riesce a farlo grazie ad un’architettura proposta molto molti anni fa: l’autoencoder.
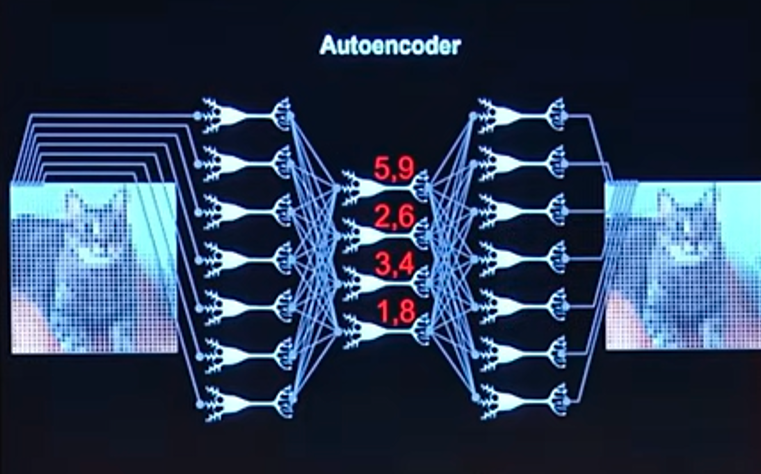
L’autoencoder è rete neurale identica a quella che abbiamo visto precedentemente, dal punto di vista strutturale, cambia solo il task, ovvero il compito per il quale viene addestrata: invece di fare classificazione e regressione, questa rete deve riprodurre un input identico all’output. Cioè prendo la foto di un gattino, come nell’esempio, e insegno alla rete a riprodurre la stessa identica fotografia dall’altro lato. Si tratta della funzione identità.
Se il task è la foto del gattino in input prende i migliaia di pixel costituenti la foto del gattino. Nella figura, per semplicità, ne vengono rappresentati solo sette.
Abbiamo visto che nella rete neurale, in figura, ci solo tre layer. Il primo layer ha 7 neuroni, il secondo layer ha 4 neuroni e il terzo layer ha 7 neuroni.
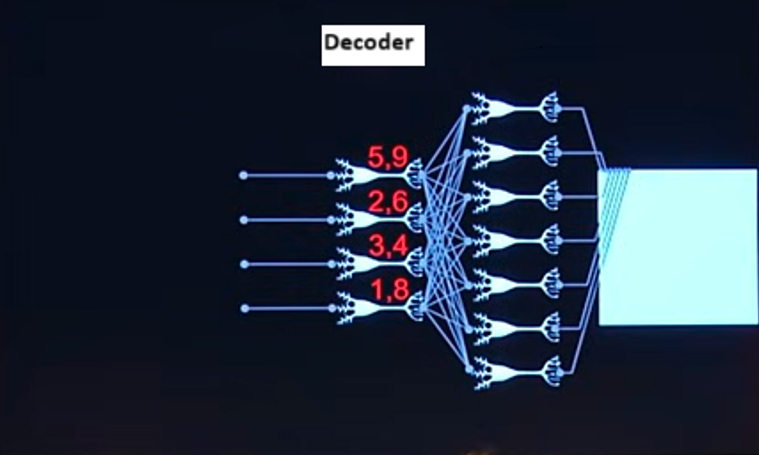
Osserviamo che nel secondo layer ci sono solo quattro neuroni. Ciò significa che la seconda metà della rete è in grado di ricostruire migliaia di pixel, di migliaia di foto, utilizzando un layer di solo quattro neuroni, ovvero con quattro numeri in input: 5,9; 2,6; 3,4 e 1,8.
La cosa incredibile è che se prendiamo la seconda parte di questa rete neurale (quella che porterà all’output) detta decoder e cominciamo a mandare in input numeri a caso, come in figura, vengono fuori foto di gattini del tutto nuove.
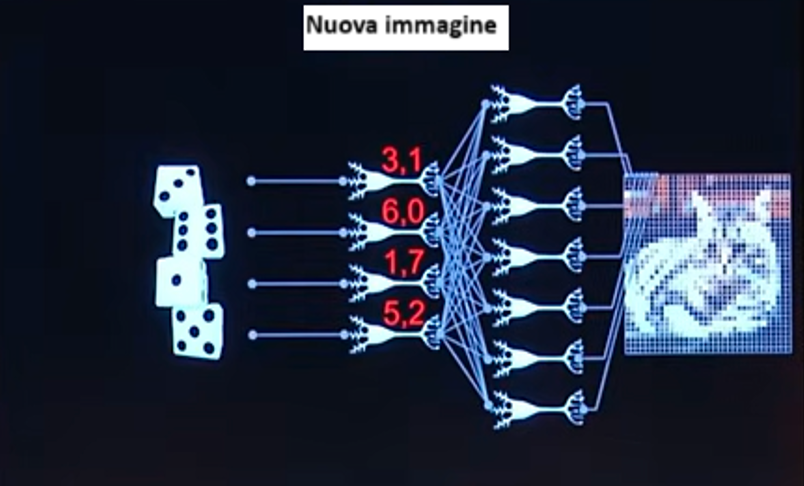
Queste nuove foto non esistono, le ha inventate la rete in quel momento, grazie al fatto che è stata precedentemente addestrata con migliaia di foto di gattini.
Ogni qual volta che una rete è in grado di fare un task generativo, ovvero di inventare foto di oggetti che non esistono, lo fa sulla base di questo presupposto: una variazione sul tema della funzione identità.
È chiaro che fin qui abbiamo lavorato con immagini, ma lo stesso identico discorso vale per delle sequenze di testo come nel caso di ChatGPT.
Torniamo, quindi, alla domanda iniziale come funziona ChatGPT?
È semplice, funziona come con i pixel delle foto, ma con una piccola differenza nell’approccio: viene usato il metodo transformer ideato da Google nel 2017.
Un paio di anni dopo, i ricercatori di OpenAI hanno addestrato GPT (oggi ChatGPT), usando il metodo transformer sul seguente task: dato un testo, indovinami qual è la parola successiva. La rete neurale fa una distribuzione di probabilità e dice: “la più probabile è questa”, così proseguendo e completando il testo.
Siccome questo modello, trainato su tutto il web, funzionava discretamente bene, i ricercatori hanno provato ad aumentare la potenza computazionale, utilizzando computer sempre più potenti.
La cosa incredibile è che aumentando la potenza del computer il modello funzionava sempre meglio: aveva, cioè, una scalabilità eccezionale.
Più è grande la potenza di calcolo più questa IA riesce a fare compiti avanzati e di ragionamento, apparentemente senza limite.
Questo non se lo aspettava nessuno.
Siamo al paradosso che noi sappiamo come costruire ChatGPT, che, abbiamo visto non essere altro che un insieme di transformer addestrati su computer giganteschi, ma non sappiamo perché funziona.
L’IA non è una scelta
Giulio Deangeli nell’ultima parte del suo intervento affronta le conseguenze sociali della inarrestabile diffusione dell’Intelligenza Artificiale.
Osserva che sembra quasi che siamo chiamati a scegliere se introdurla o meno nelle nostre vite. In realtà, come è già accaduto quando sono stati introdotti l’aeroplano, la lampadina, il telefono, internet, il cambiamento non può essere fermato, perché è epocale.
Ad esempio, queste tecniche sono in grado di moltiplicare la produttività di un individuo, di diversi fattori. Oggettivamente nessuno può rimanere competitivo se si ostina a non utilizzare queste tecniche, perché tutti i suoi colleghi o concorrenti, nella stessa giornata lavorativa producono il triplo.
È questo dal punto di vista sociale è un problema, perché sta succedendo tutto ciò che è capitato nella rivoluzione industriale, nell’arco di due anni, anziché di un secolo.
Molte persone tra pochi anni si troveranno a fare un lavoro completamente diverso da quello che facevano prima.
Allora, visto che non si può tornare indietro, bisogna farsi trovare pronti!
28/07/2025
Christian F. Solano